As a Data Services Manager, one of the services that my team provides is the extraction of data for the purposes of archival work, analysis work, or the loading of the ever growing data warehouse. One of the issues we face, is the time it takes to get the data moved over to the destination system. For one off analysis work, this can eat up a good deal of time that we could use working on larger projects.
As of the release of SQL Server 2019, we’ve added a new fancy tool to our ETL toolbox. Data Virtualization allows us to leverage the Polybase engine, to create external tables that reside on our SQL 2019 instance. This allows us to query data from external sources without the need for an ETL solution or a linked server. While the table is virtualized on our server, the workload and as well the data still live on the source system. This brings to light some considerations that we need to make prior to implementing this feature enterprise wide.
To showcase one of the performance considerations we need to factor in, we need to start off by creating our first external table. To do so, open up the latest version of Azure Data Studio (Download Here). Once open, connect to the Source SQL server and the Destination SQL Server (2019 Instance). To access the Data Virtualization tab, right click the Destination server and hit manage. You’ll see a tab on the right with Data Virtualization like below.
We will then select the Create External Table task to begin the virtualization process.
Select your Destination Database from the drop down list where the external table will live and then select what the data source type is for your source server.

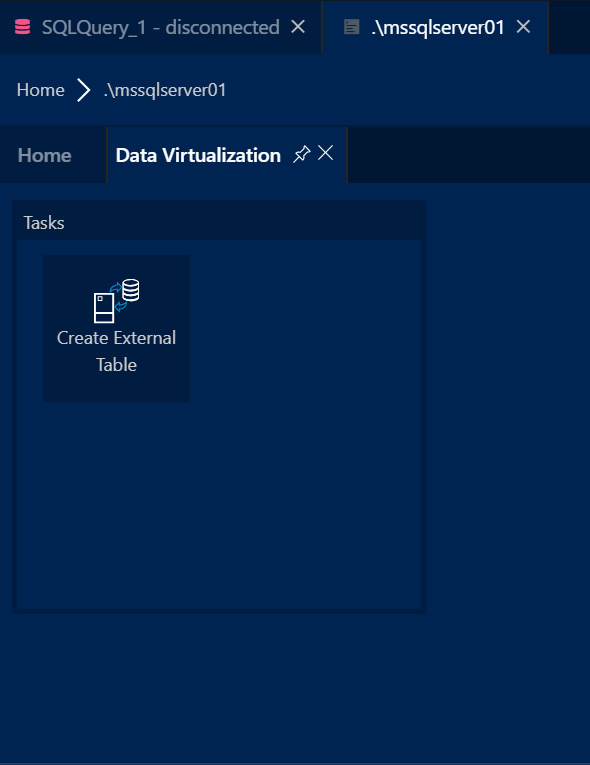
We then need to set a Database Master key, this secures the credentials used by the External Data Source. As always, please make sure to back up the keys and store them in a secure location once created.
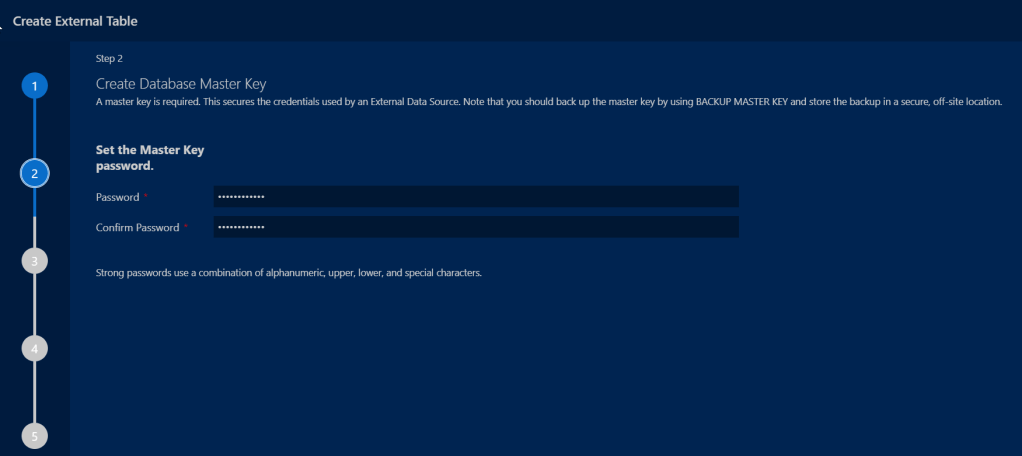
We will then define out the connection info to our source location as well as a credential to establish the connection to the source system. This user will need to be created beforehand or the creation will fail.
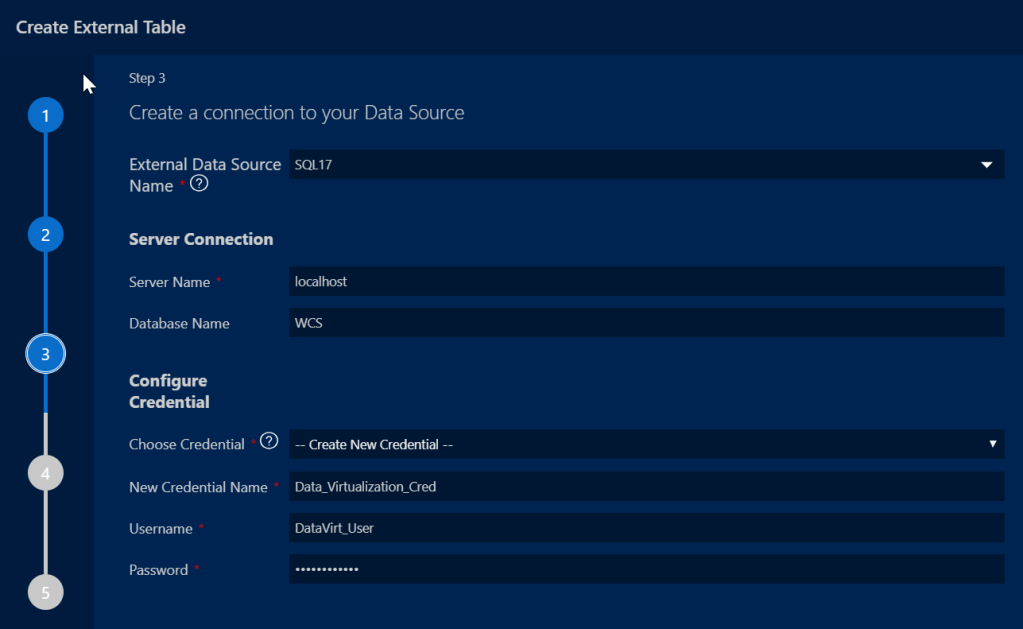
We will then define what tables we want to virtualize from the source system and adjust any mappings as required.
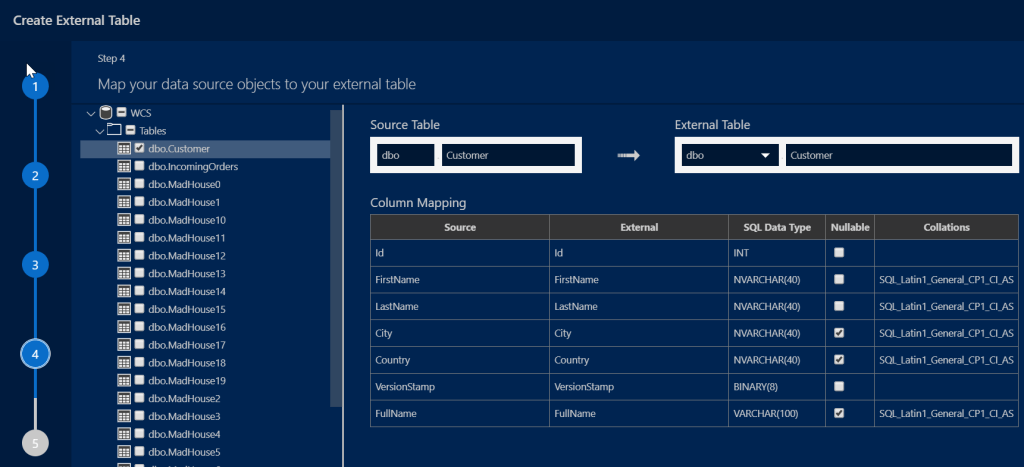
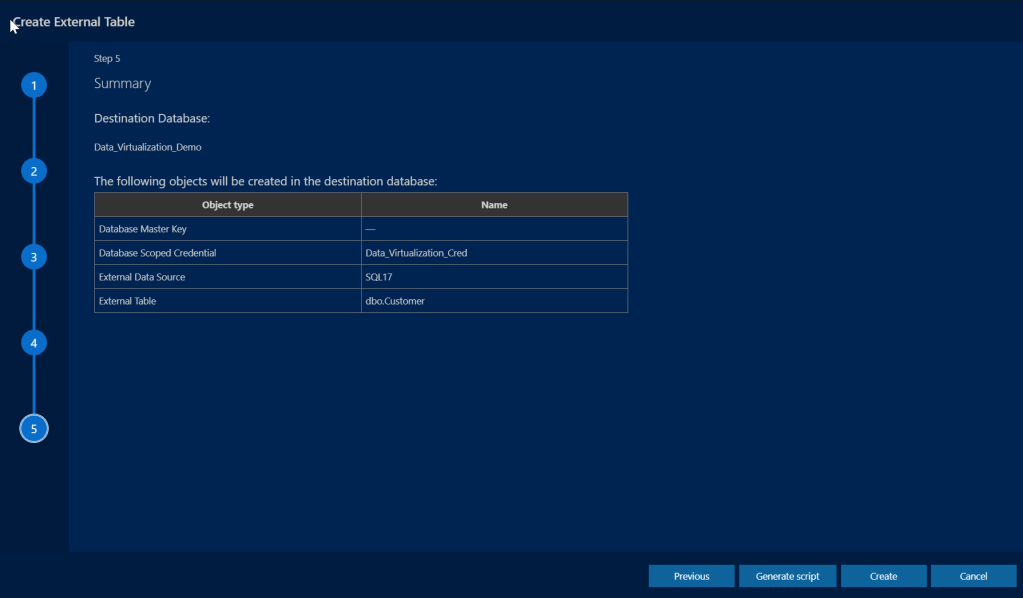
Once everything is set, hit next to review a summary of what will be created. If all looks well, you can either generate a script to create the external table or hit create to generate from the interface directly.
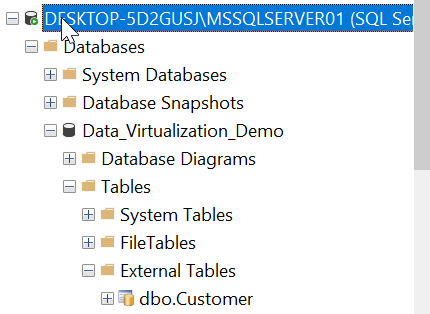
We can verify our table has been created by going to the tables section of our Destination Database in Azure Data Studio or under the External Tables Section in SSMS.
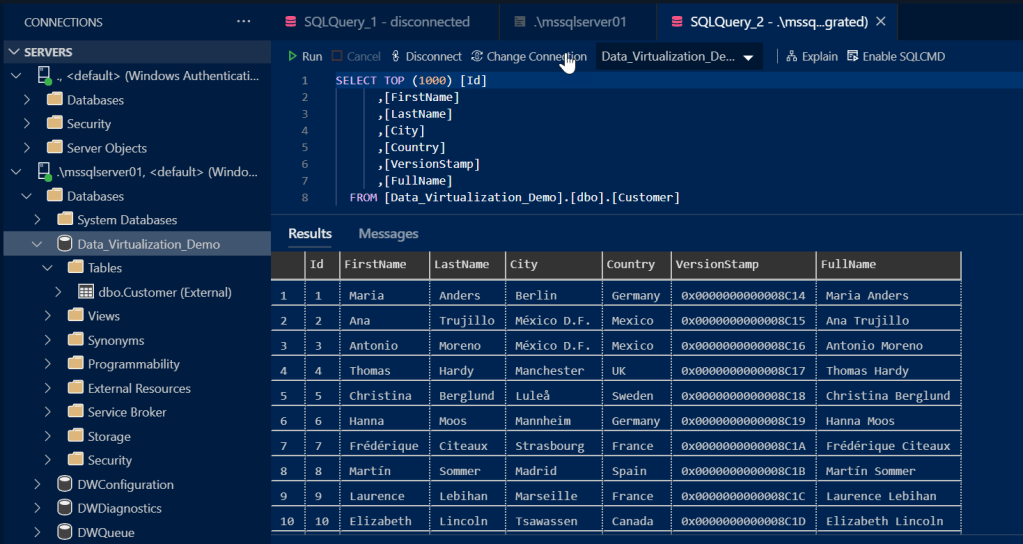
Now that we have our External Table generated, we can run an extended events session to see how the data is retrieved. We will start off by running a session on the destination and source systems and execute a Select statement against the External Table.
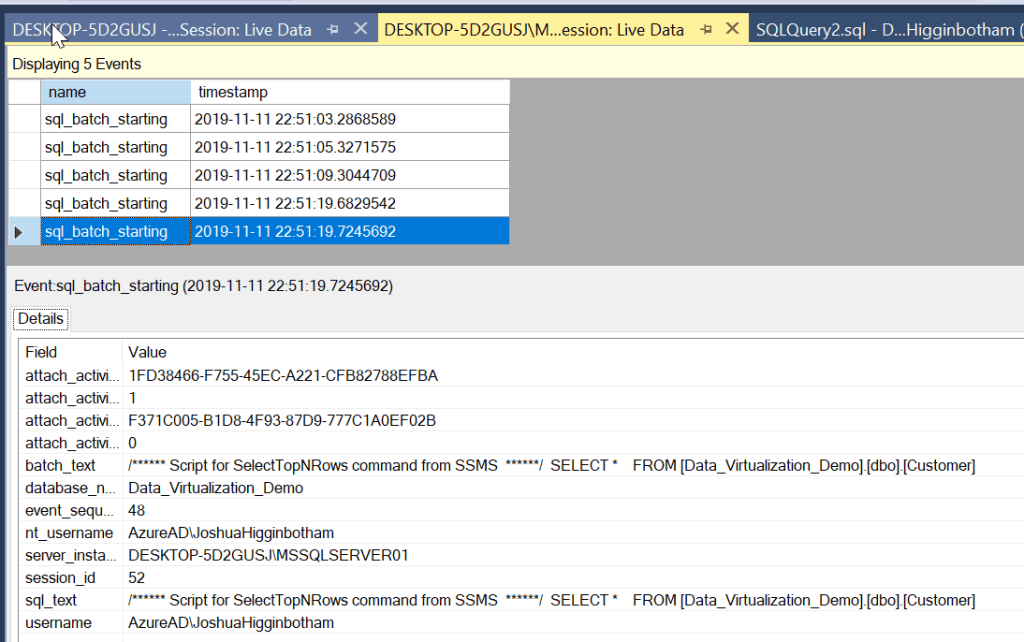
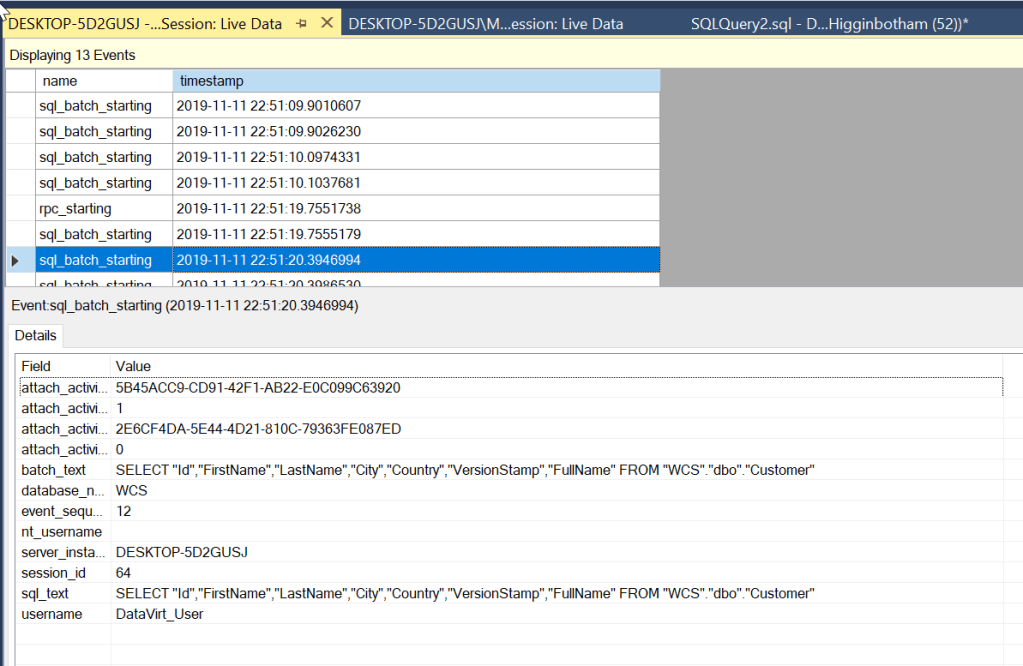
What if we take a look at the query plan for the external table.
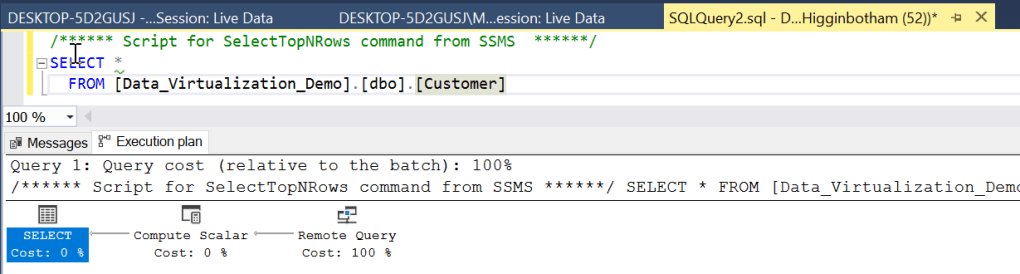
We see, that the query plan shows that the cost is on the remote query, which we expect based on our current knowledge around Data Virtualization.
So we have an idea of how this all works now, well at least from a high level. What are some considerations that we need to make when we roll this into our enterprise? How does this affect our Disaster Recovery strategy? What happens if someone decides to query every record in the external table? Or better yet, what happens if the schema changes on the source side, what do we do to correct it on the destination side? Look out for more blog posts on this topic where we will answer some of these concerns.
Categories: SQL Server 2019

Thanks for the post. Looking forward to more posts on data virtualization and challenges to overcome
LikeLike