The popularity of Python continues to grow and grow as days go on. As companies begin to adopt cloud first approaches and the move to the Modern Data Warehouse, it’s important that as BI Developers, we are working towards building our skillsets to be ready for when the company gives the greenlight for the cloud. The problem with this is how to learn the skills for the cloud if these skills to work in the cloud are lacking. While you can learn a good deal working through the amazing line up of tutorials provided by Microsoft from their MS Learn platform, there will never be a replacement for working with real data that you deal with each day. So what can we do?
First of all, you don’t have to wait till you’re in the cloud to start using some of the languages or technologies you’ll find in the cloud. You can begin to work with languages like Python, while on-premises, to build your skillset and knowledge of the language ahead of time. Once in the cloud, you can hit the ground running. While this post will not cover what you need to learn, we will cover an important step to being able to work with Python while on-premises and that’s automation. There are a ton of ways that you can solve this issue. From open source solutions like AirFlow or Luigi, to native scheduling tools like Windows Task Scheduler or SQL Agent Jobs, we can set up scheduled runs of solutions. While AirFlow and Luigi are great options for what we are wanting to do, the spin up of the environments you’ll need to be able to use it takes time and effort that you may lack. You also have to add that to your list of systems you need to maintain, which doesn’t tend to make your support teams happy. If your end goal is to adopt the cloud, then my suggestion would be to use something we natively use each say as Developers within the SQL Server space.
So how do you setup SQL Agent to run python scripts?
First off, we need to figure out what server we are going to run these from. For me, it was our SQL Servers dedicated to SSIS. Once this is figured out, we then need to do a custom install of Python. The key here, is to make sure when you install python, you install it across the server itself and not at the user level. Once installed, we can then move to SQL Agent to complete the rest of the work. You’ll need to make sure the service account that you are running SQL Agent with has both permissions to install libraries with python as well as permissions to the directory that your python scripts live. Once permissions are set we can start building out our SQL Agent Job.
Step 1:
We need to make sure our libraries are installed to the server as well as ensuring these libraries are updated as new releases are pushed. To do so, we can add a step that will run our requirements.txt file stored within our project directory that lists out our Library dependencies. Below is an example of what this step will look like.

This command is based off the type of python distribution that I am using (Python.org). If you’re using a different distribution of python like Anaconda, then this command is going to be different.
Step 2:
Next, we will need to make a call to our python script that will run our pipeline.
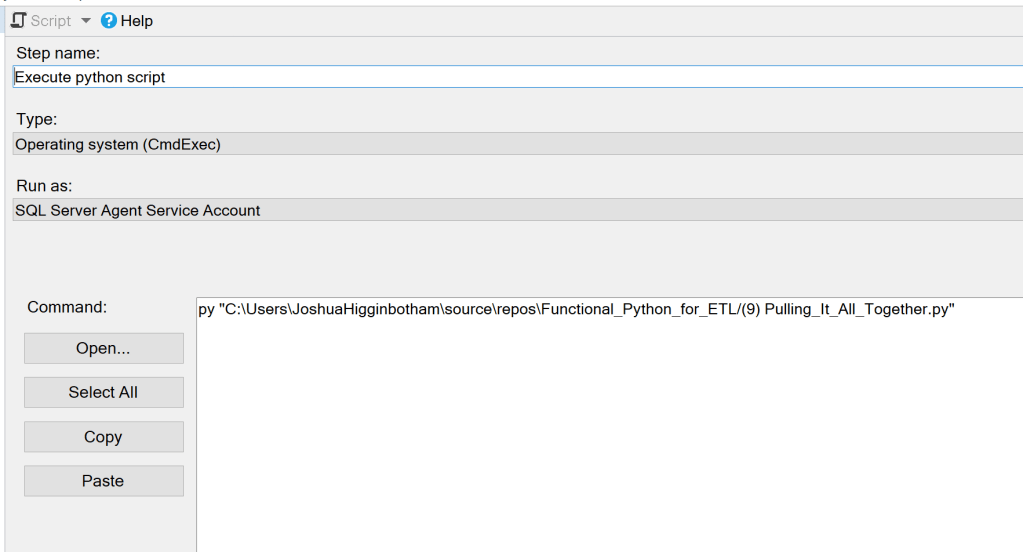
Depending on the type of operation that you are completing within your pipeline, you may need to make some adjustments to account for the difference in the working directories between your systems. An example of this could be calling files within your project directory to complete some type of operation. An example of this could be if you’re using a config.ini file to set the value of variables based off the environment you are running from. To pull variables from this file, when we initialize the variable within our script, we need to call it using something like this.

Once you have this created, then you’re good to go to kick off your job to test. If the job fails, the issue (thankfully) will output to the job log with the error that occurred. If you’d like to work through this example without having to build out python code yourself, you can pull down the code from my repo here.
Categories: Data Engineering

1 reply ›